

Step-by-Step Guide to Linear Regression from Scratch
Build and explain a linear regression model with this step-by-step tutorial.


This is beginner friendly, you don't need any prerequisites and I'll explain each and every single line of code and mathematical logic as simply as possible so jump right in!
There are 3 things I'll be covering in this article
Linear Regression
Mathematical Logic for Linear Regression
Gradient Descent
What is Linear Regression?
Think of it this way: when you have a dataset with x and y values, and there is a linear relationship between how your y values change with respect to your x values, you can define a function of x to get the values of y. In linear regression, the relationship between x and y is usually linear, meaning the function is similar to the equation of a straight line. The graph below shows the "Linear Relation" graphically.

The equation for above graph is given below (Try to find it yourself!)
$$y = 4x + 20$$
A linear relation is a statistical term used to describe a straight-line relationship between two variables. Simply put, your input and output grow at a constant rate.
Linear relationships can be shown either in a graph, like the one above, or as a mathematical equation in the form
$$y = mx + b$$
$$\displaylines{ Here \quad m = \frac{y_2 - y_1}{x_2 -x_1} =\frac{rise}{run}=slope \\ b = y\;\;intercept }$$
The above equation can also be written as:
$$\displaylines { y = \theta_0 + \theta_1x \\ Here \;\; \theta_0 \;\; is \;\; called \;\; bias \\ \theta_1 \;\; is \;\; the \;\; slope }$$
Here, x is a single input/dimension/feature (feature is a more commonly used term for input in machine learning). For multiple features, the above equation can be converted to the following:
$$\displaylines{ y = θ_0x_0 + θ_1x_1 + θ_2x_2 + ... + θ_nx_n \\ y = \sum_{i=0}^n θ_ix_i \\ where \;\;\; x_0 = 1 \\ \\ Here \;\; \theta \;\; are \;\; parameters \\ \qquad x \;\; are \;\; features \\ \qquad y \;\; is \;\; the \;\; output }$$
Now you know what a linear relation is and its equation. Linear regression is all about finding a line of best fit or rather finding the equation of our line of best fit.
What is line of best fit?
The line of best fit is an imaginary line we draw in our data set that has the minimum distance from all the observations (scattered data points). We use this line to make predictions or estimates of the y (dependent variable) value based on its corresponding x (independent variable) value.
The line of best fit depends on the values of our parameters θ, such that plugging in x values into our function gives us the desired y values. This means our goal is to find the best θ values for the given dataset.
To achieve this, we start with an initial θ value and adjust it in iterations to fit the dataset better. We use an algorithm called Gradient Descent to change the θ value. It works by minimizing our error values. We can use various error functions, like mean absolute error or mean squared error, to calculate our error values. These are also called loss functions.
We will be using the following loss function :
$$\displaylines{ J(\theta) = \frac{1}{2}\sum(y_i - \hat{y}_i)^2 \\ here \;\; \hat{y}_i - predicted\;\; value \\ \quad \; y_i - actual\;\; value }$$
Gradient Descent
For gradient descent algorithm :
we start with some θ (say θ = 0)
Then we keep changing θ to reduce J(θ).
Here's a pic to show how gradient descent works:
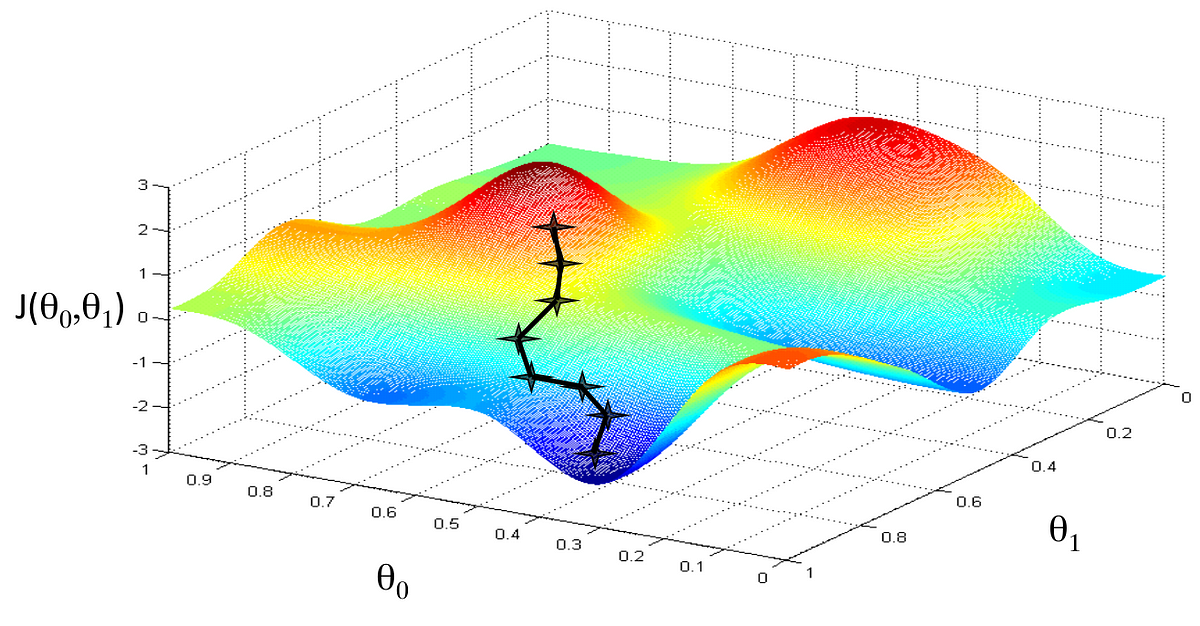
We change the θ value by a small step continuously until we get consistent values, indicating we have reached a local optimum. This process is like descending a mountain from the top to the bottom. The bottom of the mountain represents low error and values close to the actual data. Here is the equation for gradient descent:
$$\displaylines{ \theta_j : = \theta_j - \alpha \frac{\partial}{\partial \; \theta_j} J(\theta) \\ \alpha - Learning \;\; Rate \\ }$$
We take the partial derivative of J(θ) with respect to θ because we are only interested in how θ changes. The derivative of a function shows the steepest descent. The learning rate usually depends on the specific problem, but in theory, we use 0.01 as a starting value and adjust it as needed.
Here is the math for the gradient descent partial derivative. I simplified it as much as possible, but try it yourself because it's more fun that way!
$$\displaylines{\frac{\partial}{\partial \; \theta_j} J(\theta) = \frac{\partial}{\partial \; \theta_j}\;\frac{1}{2}\sum [(h(x^i) - y^i)^2] \\ = \sum2\frac{1}{2}(h(x^i) - y^i)(\frac{\partial}{\partial \; \theta_j} ((θ_0x_0 + θ_1x_1 + θ_2x_2 + ... + θ_nx_n ) - y^i)) \\ Simplifying \;\; (\frac{\partial}{\partial \; \theta_j} ((θ_0x_0 + θ_1x_1 + θ_2x_2 + ... + θ_nx_n ) - y^i)) \;\; gives \;\; us\;\; x^i \\ This \;\; is \;\; because \;\; everything \;\; else\;\; is \;\; a \;\; constant\;\; which\;\; equates\;\; to \;\; 0\\ \\ = \sum(h(x) - y) x^j }$$
The formulas used are:
$$\displaylines{ \frac{\partial}{\partial x}x^n = nx^{n-1} \\ \frac{\partial}{\partial x}c = 0 \\ \frac{\partial}{\partial x}ax = a }$$
So the equation for θ will be the following
$$\theta_j := \theta_j - \alpha\sum(h_θ(x^i) - y^j)x_j^i)$$
Now let's implement this in code and build a linear regression model from scratch:
I'll be using this salary dataset for linear regression from Kaggle as data for my model.
First, we'll import pandas to read our CSV (comma-separated values) file, matplotlib.pyplot to visualize our data, and numpy since we're working with large arrays.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
Now we'll import our data and visualise it in a graph
df = pd.read_csv("/kaggle/input/salary-data-dataset-for-linear-regression/Salary_Data.csv")
"""
Here I used "/kaggle/input/salary-data-dataset-for-linear-regression/Salary_Data.csv"
because I'm doing this in my kaggle workspace if you're doing this
in your IDE then just give the path to your csv file here.
"""
plt.scatter(df.YearsExperience, df.Salary)
plt.show()
The "read_csv" method reads and opens our data file, returning a pandas DataFrame. The "plt.scatter" method plots our data points on a graph, and the "plt.show" method displays the graph. The code above produces the following output. It's always important to analyse and visualise our data to determine which algorithm fits it best.

As we can see, the data appears to be scattered in a straight line. Therefore, we can confidently use linear regression, as we can fit a line of best fit here, as shown below:

Now let's start preparing our data
We first need to separate the data into input and output parts, i.e., X and y.
m = df.shape[0] X = np.hstack((np.ones((m,1)), df.YearsExperience.values.reshape(-1,1))) y = np.array(df.Salary.values).reshape(-1,1) theta = np.zeros(shape=(X.shape[1],1))Here In the first line m = df.shape[0] gives the number of rows we have in our dataset
Now to separate X values we're first making
x₀ = 1 and x₁ = value from dataset because of the following equation where we've clearly seen that x₀ must equal 1
$$\displaylines{ y = θ_0x_0 + θ_1x_1 + θ_2x_2 + ... + θ_nx_n \\ y = \sum_{i=0}^n θ_ix_i \\ where \;\;\; x_0 = 1 \\ }$$
We used "np.hstack" to add the value 1 before every x data point, so it is internally represented as [1, value].
The "reshape" function is used to convert all the data points into a single column with 30 rows (The 30 here is only valid to the dataset I'm using your dataset might change this value). This is done using (-1, 1), where "-1" tells the program to figure out the dimension of the array by itself. For a clearer understanding, refer to the numpy documentation linked at the end of this blog.
The Y values are also organized into an array with 30 rows and a single column using the same "reshape" method and -1 notation.
Since we have 2 theta values, θ₀ and θ₁, we create an array with 2 rows and 1 column, initializing both theta values to 0 using the "np.zeros" method.
Now we have all the data we need to implement our algorithm
Gradient Descent :
$$\theta_j := \theta_j - \alpha\sum(h_θ(x^i) - y^j)x_j^i)$$
We will use the above equation to write our gradient descent function. I will refer to it as the gradient descent equation in this section, so please remember that.
One important thing to note is the h(x) function value, which is simply the dot product of the X and theta matrices:
$$h_\theta(x^i) = \theta_0x_0 + \theta _1x_1$$
Let's create a function named "GradientDescent":
def GradientDescent(theta, X, y, alpha=0.01, epochs=300):
for _ in range(epochs):
for j in range(len(theta)):
error = 0
for i in range(len(X)):
h = X.dot(theta)
error += (h[i][0] - y[i][0]) * (X[i][0])
theta[j] -= alpha * error
Now let me explain each line of code above:
First, the parameters:
The theta parameter is the array of our theta values, which are currently initialized to 0.
X is the input array.
y is the expected/actual output values array.
alpha is our learning rate.
epochs is the number of times we will iterate.
Now we're going to repeat the gradient descent for the number of epochs, which in this case is 300 times, with alpha set to 0.01.
Now, take a look at the gradient descent equation we derived earlier.
We will update our theta value at each index j, which is why we iterate over all theta indices using the variable j in our for loop.
Now we need to calculate the error, multiply it by our learning rate, and subtract that value from our current theta value.
To calculate the error, we'll use the gradient descent equation. The error here is
$$(h_\theta(x^i) - y^i) x^i$$
The value of h[i][0] is obtained by performing a dot product of our X and theta arrays.
After calculating the error, we subtract alpha times the error from our theta, which is:
theta[j] -= alpha \ error*
And that's it! We've successfully defined our GradientDescent function.
Now we just need to call the function with the correct arguments, and we're done. It will update our theta values to a local optimum, and we can use these theta values to predict y values.
GradientDescent(theta, X, y)
plt.scatter(df.YearsExperience, df.Salary, color="black")
plt.plot(list(range(0,14)), [theta[1][0] * x + theta[0][0] for x in range(0, 14)], color="red")
plt.show()
We called the GradientDescent function with the arguments "theta, X, y".
Since our theta values are updated in the GradientDescent function, we can now calculate the predicted line of best fit and plot it on the graph to see how the line fits with our data.
First, we scatter our data points and color them black.
Since our X values range from 0 to 14, we will draw a straight line on the graph for all values from 0 to 14 using the line equation [ mx + b ], with our theta values θ₀ = b and θ₁ = m. This gives us the following graph and line of best fit which is colored red.

That's perfect.
Now, here is the complete code for our linear regression:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv("/kaggle/input/salary-data-dataset-for-linear-regression/Salary_Data.csv")
m = df.shape[0]
X = np.hstack((np.ones((m,1)), df.YearsExperience.values.reshape(-1,1)))
y = np.array(df.Salary.values).reshape(-1,1)
theta = np.zeros(shape=(X.shape[1],1))
def GradientDescent(theta, X, y, alpha=0.01, epochs=300):
for _ in range(epochs):
for j in range(len(theta)):
error = 0
for i in range(len(X)):
h = X.dot(theta)
error += (h[i][0] - y[i][0]) * (X[i][0])
theta[j] -= alpha * error
GradientDescent(theta, X, y)
plt.scatter(df.YearsExperience, df.Salary, color="black")
plt.plot(list(range(0,14)), [theta[1][0] * x + theta[0][0] for x in range(0, 14)], color="red")
plt.show()
To predict new values, simply take the dot product of the new input values with our "theta" array, and you'll get your predicted values.
Congratulations on making it this far; we're all done.
I'll be teaching about Batch Gradient Descent, Stochastic Gradient Descent, and the Normal Equation for linear regression in my next article, so stay tuned!
If you enjoyed this article, please consider buying me a coffee.
Here are a few documentation links for the modules I used in this code:
Follow me on my social media and consider subscribing, as I'll be covering more Machine Learning algorithms "from scratch".